Finding links on a webpage
Web browsers operate (in part) by turning structured text into a graphical layout. For instance, the structured text found here contains the instructions that tell a web browser to render the following website:
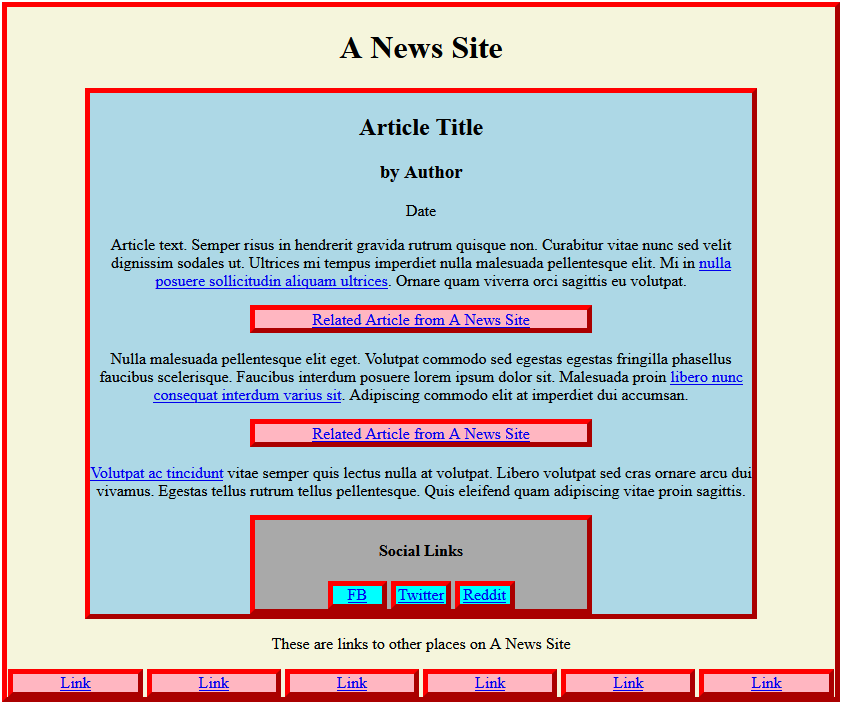
Websites are primarily composed of this structured text, called HTML. You can examine the HTML for any webpage by right clicking on a page and selecting the “Inspect Page Source” or entering developer mode in your browser.
Primary Source Scraper reads the HTML from news websites to find all the links in the page. PSS uses the information in each link to determine whether that link is an internal link (i.e. goes back the the same site) or an external link (i.e. links to a different site). This turns out to be very easy, and PSS can do this kind of analysis on any webpage.
If link analysis is so easy, why aren’t all sites supported?
If you’re a regular user of Primary Source Scraper, you’ve probably come across this message:
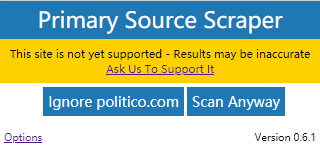
While many news websites look similar in structure to the basic example given above, every news site is different. When you look at a news article after your browser has turned it into a graphical layout it’s easy to understand which part of a webpage is the article and which parts are not. It’s less easy to do that by only looking at HTML, and not every website has an obvious boundary in that HTML between the article and everything else.
Most news sites have lots of links to their own site outside of the article. This is normal and reasonable - as a news consumer you’re likely to want to read other articles related to what you’re reading. It’s not fair for PSS to count these as internal links because they’re not attempting to source a claim.
Most news sites also have links to social media, either to allow you to share an article you’re reading or to link to an author’s profile information. It’s not fair for PSS to count these as external links - and these definitely don’t count as sources for claims in the article.

Adding support for a site requires human analysis to understand what parts of a webpage count as article and which parts count as everything else. On some websites this analysis is easy, but other sites can be quite complex. As this project grows PSS will support more websites, but we need help from our users to understand which sites we should support first.
Scanning unsupported sites
As of version 0.5.12 there’s a “Scan Anyway” button that will allow you to view the same external link details you would normally get from a supported page. These results are likely to have errors:
- The Internal / External Link Ratio chart will likely be very inaccurate for unsupported pages you choose to scan.
- Some external links are likely to include social media sharing links that are unrelated to the article content.
- Some external links are likely to be other domains owned by the same website.